Voice, speech, and sound recognition
How AI and Edge technology are helping the evolution of voice recognition, speech recognition and sound recognition systems
Advances in artificial intelligence software coupled with low-power, high-performance edge hardware are allowing many applications to benefit from the technologies affordably in terms of power budget, size, and cost.
In this article, we look at speech and sound recognition system basics, some application areas now using the technology, some underlying algorithms, and examples of both speech recognition and sound recognition implementations.
Early speech recognition systems were often frustrating to use. Most of us can no doubt remember customer service telephone systems that obstinately refused to understand or act on our commands. More recently, though, improving artificial intelligence (AI) technology has meant that speech recognition can be used reliably not only in traditional areas like telephone customer service but in many other applications as well. These include listening to machine sounds and vibrations to analyse their health and identify any need for preventative maintenance.
Below, we look at speech recognition and voice recognition, and then at an example of sound recognition technology.
In fact, many systems use both speech recognition and voice recognition. These are not interchangeable names for the same technology; they have distinct and well-defined meanings.
At its simplest, we can say that voice recognition identifies who is saying something, while speech recognition understands what they are saying.
Speech and sound system basics and applications
Speech recognition technology uses natural language processing or NLP and machine learning (ML) to translate human speech.
Engineers used the term automatic speech recognition, or ASR, in the early 1990s to stress that speech recognition is machine processed. But today, ASR and speech recognition are synonymous.
It has taken years of deep research, machine learning, and implementing artificial intelligence to develop speech recognition technologies used in today’s voice user interfaces (VUIs).
Speech recognition relies upon 'feature analysis', which is 'speaker-independent' voice recognition. This method processes voice input using phonetic unit recognition and finds similarities between expected inputs and the actual digitized voice input. Simply put, it matches a user’s speech to generic voice patterns.
Highly accurate speaker-independent speech recognition is challenging to achieve as accents inflections, and different languages thwart the process. Speech recognition accuracy rates range from 90% to 95%.
Here’s a basic breakdown of how speech recognition works:
- A microphone translates the vibrations of a person’s voice into an electrical signal.
- A computer or similar system converts that signal into a digital signal.
- A preprocessing unit enhances the speech signal while mitigating noise.
- The speech recognition software analyses the signal using acoustic modeling to register phonemes, distinct units of speech sound that represent and distinguish one word from another.
- The phonemes are constructed into understandable words and sentences using language modeling.

Figure 1: Speech recognition process
Applications for speech recognition:
- Speech-to-text applications are increasingly common and accurate. For example, Microsoft Word has a built-in Dictate function that uses speech recognition.
- Voice Control in industrial areas, where gloves and work processes make manual control difficult, or in the medical field, where important events can be documented, and functions activated by voice without taking hands or eyes off the ongoing activity.
- Smart home devices use speech recognition technology to carry out household tasks such as turning on the lights, boiling water, adjusting the thermostat, and more.
- Automotive: In-car speech recognition systems have become a standard feature for most modern vehicles. Car speech recognition is important in allowing the driver for keep their eyes on the road and hands on the wheels. Other uses include initiating phone calls, selecting radio stations, setting up directions, or playing music.
Voice recognition and speech recognition are similar in that a front-end audio device (microphone) translates a person’s voice into an electrical signal and then digitisesit.
While speech recognition will recognise almost any speech (depending on language, accents, etc.), voice recognition applies to a machine’s ability to identify a specific users’ voice. Voice recognition depends on a recorded template of a user’s voice, called 'template matching'. A program must be 'trained' to recognise a user’s voice.
First, the program will show a printed word or phrase that the user speaks and repeats several times into the system’s microphone to train the voice recognition software. Next, the program computes a statistical average of multiple samples of the same word or phrase. Finally, the program stores the average sample as a template in its data structure.
Voice recognition accuracy rates are higher than speech recognition — 98%. Also, devices that are speaker-dependent can provide personalised responses to a user.

Figure 2: Voice recognition process
Applications for voice recognition:
- Security: Vocal biometrics uses a person’s speech to authenticate them. Users might be required to say their name aloud during log-ins rather than typing a password.
- Fintech and healthcare: Vocal biometrics can be used in Fintech to authorise transactions and to guarantee they are genuine and consented from the account owner. Voice biometrics can also restrict access to authorised personnel in healthcare, where maintaining patient confidentiality is of the utmost importance.
- Intelligent virtual assistants like Google’s Assistant will provide individualised responses, such as giving calendar updates or reminders, only to the user who trained the assistant to recognise their voice.
- Voice Picking: Warehouses have integrated voice recognition to complete tasks and keep workers hands-free.
Speech recognition algorithms
Modern statistically-based speech recognition systems use various algorithms, including hidden Markov models (HMMs), and Recurrent Neural Networks (RNNs).
Hidden Markov Models: Modern general-purpose speech recognition systems are based on hidden Markov models. These are statistical models that output a sequence of symbols or quantities. HMMs are used in speech recognition because a speech signal can be viewed as a piecewise stationary signal or a short-time stationary signal. In a short time scale (e.g., 10 milliseconds), speech can be approximated as a stationary process. Speech can be thought of as a Markov model for many stochastic purposes.
Another reason why HMMs are popular is that they can be trained automatically and are simple and computationally feasible to use. In speech recognition, the hidden Markov model would output a sequence of n-dimensional real-valued vectors (with n being a small integer, such as 10), outputting one of these every 10 milliseconds. The vectors would consist of cepstral coefficients, which are obtained by taking a Fourier transform of a short time window of speech and decorrelating the spectrum using a cosine transform, then taking the first (most significant) coefficients.
Each word, or (for more general speech recognition systems), each phoneme, will have a different output distribution; a hidden Markov model for a sequence of words or phonemes is made by concatenating the individual trained hidden Markov models for the separate words and phonemes.
A recurrent neural network (RNN) is a type of artificial neural network that uses sequential data or time series data. These deep learning algorithms are commonly used for ordinal or temporal problems such as language translation, natural language processing (NLP), speech recognition, and image captioning; they are incorporated into popular applications, such as Siri, voice search, and Google Translate. Like feedforward and convolutional neural networks (CNNs), recurrent neural networks utilisetraining data to learn. They are distinguished by their 'memory' as they take information from prior inputs to influence the current input and output. While traditional deep neural networks assume that inputs and outputs are independent of each other, the output of recurrent neural networks depends on the prior elements within the sequence. While future events would also help determine the output of a given sequence, unidirectional recurrent neural networks cannot account for these events in their predictions.
One popular RNN architecture is called Long short-term memory (LSTM). This addresses the problem of long-term dependencies. That is, if the previous state that is influencing the current prediction is not from the recent past, the RNN model may not be able to accurately predict the current state. As an example, let’s say we wanted to predict the italicised words in the following, 'Alice is allergic to nuts. She can’t eat peanut butter'. The context of a nut allergy can help us anticipate that the food that cannot be eaten contains nuts. However, if that context was a few sentences prior, then it would make it difficult, or even impossible, for the RNN to connect the information. To remedy this, LSTMs have 'cells' in the hidden layers of the neural network, which have three gates–an input gate, an output gate, and a forget gate. These gates control the flow of information, which is needed to predict the output of the network.
A practical Edge-type speech recognition example – offloading the central processor to improve performance, while managing power demand
Within Natural Language Processing (NLP), Machine Learning (ML) and Deep Learning (DL) are being applied to produce new automatic speech recognition (ASR) solutions. Generally, most solutions are compute-intensive and require high-end graphics processing units (GPUs) or cloud-based inference. However, GPUs are power hungry and cloud-based solutions raise questions about privacy and data security, as well as latency.
Field Programmable Gate Arrays (FPGAs) solutions have evolved to include the combination of Processor Subsystems combined with traditional FPGA logic, enabling power-efficient, edge-base solutions for these traditionally compute-intensive tasks. Due to these advantages, there has been a trend to target ever more complex ML/DL solutions on edge-based FPGA system-on-chip (SoC) devices.
Within the Xilinx WiKi is a description of one such implementation: 'Automatic Speech Recognition on Zynq UltraScale+ MPSoC'. The solution is based on a Xilinx edge device using the Vitis accelerated flow. (See Fig. 3 below)
Vitis™ unified software platform overview
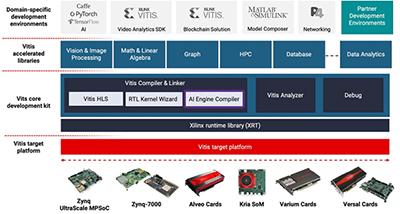
Vitis accelerated flow is part of Xilinx’s Vitis™ unified software platform. This includes:
- A comprehensive core development kit to seamlessly build accelerated applications
- A rich set of hardware-accelerated open-source libraries for AMD FPGA and Versal™ ACAP hardware platforms
- Plug-in domain-specific development environments, enabling development directly in familiar, higher-level frameworks
- A growing ecosystem of hardware-accelerated partner libraries and pre-built applications
Platform based flow: The Vitis development environment enables portability from a platform to platform whether you are porting from proof of concept (PoC), development board, or custom board.
Figure 3: Xilinx Vitis unified software platform overview
The model chosen for the automatic speech recognition (ASR) task is DeepSpeech2 , based on Baidu’s Deep Speech research paper.DeepSpeech2 is an end to end speech recognition model proposed in December 2015. It is capable of outputting English text from audio speech as input.
The designs are evaluated on a Zynq UltraScale+ MPSoC ZCU102 evaluation kit . This kit features a Zynq UltraScale+ MPSoC device with a quad-core ARM Cortex-A53, dual-core Cortex-R5 real-time processors, and a Mali-400 MP2 graphics processing unit based on Xilinx's 16nm FinFET+ programmable logic fabric (See fig.4). The ZCU102 supports all major peripherals and interfaces enabling development for a wide range of applications.
Improved performance with optimised power management. The flexibility of the Zynq UltraScale+ MPSoC not only enables the improved-performance speech recognition system as described below, but also facilitates optimised power management – an essential requirement for devices intended for edge implementations.
Common techniques for power management in embedded systems include, but are not limited to:
- Managing processor utilization for power
- Active/inactive core management
- Frequency scaling
- Clock gating
With the Zynq UltraScale+ MPSoC, not only can the designer use the above techniques, but software tasks can be moved, via C to HDL tools, to programmable logic (PL). This offloading of software tasks to coprocessors has demonstrated not only higher performance processing, but also higher performance per watt.
Based on the Xilinx UltraScale™ architecture, the Zynq UltraScale+ MPSoC enables extensive system-level differentiation, integration, and flexibility through hardware, software, and I/O programmability. It also delivers a heterogeneous multi-processing system with integrated programmable logic and is designed to meet embedded system power management requirements
The processing system provides power/performance scaling via three distinct levels of processing systems: the high-performance application processors, the real-time processors, and the energy-efficient platform management unit, each with its own power management capabilities. The latest generation programmable logic provides its own power reduction and management capabilities via next-generation lower power hard IP and enhanced performance soft IP.

Figure 4: Zynq™ UltraScale+™ EG MPSoC block diagram
The modelling process and results
Three sets of results are obtained:
- Two based on processing system (PS) only
- The third design offloads some computation on the programmable logic (PL) in combination with the PS
The three major steps followed in this approach are shown in Fig 5. below.

Figure 5: The three major steps of the Zynq edge device approach
The three major blocks are:
- Feature Extraction: Information must be extracted from an input audio file in a form that can be interpreted by a deep learning model. This information extraction step is termed as a feature extraction step. For a speech recognition task, a spectrogram is generated from the audio file and given as an input to the deep learning model.
- Deep Learning Model: A trained deep learning (DL) model receives input from the feature extraction block and predicts the output. For speech recognition tasks, the DL models are generally based on a Long short-term memory (LSTM) model.
- Decoder: The output of the DL model is numbers/probabilities, which need to be interpreted as the final prediction. The Decoder performs this task, and it is generally based on a CTC (Connectionist Temporal Classification) decoder. The decoder finally predicts the equivalent text of the input audio.
Brief overview of DeepSpeech2
Baidu's DeepSpeech2 is an end-to-end solution for automatic speech recognition (ASR). The model intakes normalised sound spectrogram as an input (generated by feature extraction step) and generates a sequence of characters, which are then reduced to a final prediction by a decoder. The general architecture of the DeepSpeech2 model is shown by the left image in Fig. 6 below. The number of CNN and RNN layers can vary, as mentioned in the DeepSpeech2 paper.

Figure 6: Architecture of DeepSpeech2 model
The model receives a normalised spectrogram. The input is then passed through a set of convolutional (CNN) layers. After the convolutional layers, there is a stack of LSTM layers (it can be a simple Recurrent Neural Network (RNN), or Gated Recurrent Unit (GRU) as well). These LSTM layers are generally bi-directional layers, which process frames in both forward and backward directions. The LSTM layers are then followed by a fully connected (FC) layer. The output of the FC layer is then passed to a CTC-based decoder to predict the final text output.
The architecture used for benchmarking is shown on the right side of Fig.6 above. The model implemented consists of a stack of bi-directional LSTM layers along with other layers such as CNN and FC. The implementation is a dense model (not pruned) that is deployed without quantization and leverages a 2-layer CNN and a 5-layer bi-directional LSTM. The numbers mentioned in the figure correspond to a convolutional layer representing input channels, output channels, filter height, filter width, stride height, and stride width respectively. The input size and the number of hidden units in each gate are also mentioned for all the LSTM layers (input size, number of hidden units).
The three solutions
PS Only: The complete DeepSpeech2 pipeline is implemented using C++. It is developed in-house from scratch and no external high-end libraries or IP cores are used. The design is compiled and built using the Vitis acceleration flow and then tested on ZCU102 board using the executables generated by Vitis. The initial version of the implementation was profiled for 10 audio samples, with the samples ranging from 1 second to 11 seconds.
This process resulted in the following major takeaways:
- The time taken for the initial PS-only solution computing the complete pipeline was on average equal to 6.77 times the audio length.
- The combined time taken by feature extraction and post LSTM block is less than 1% of the total time taken.
- On average, the time spent in computation of the CNN block is around 11% for all the audio samples.
- As expected, the LSTM block is the most expensive block and consumes around 89% of the total computation time.
After profiling the initial PS-only solution, a multi-threaded design is then implemented to achieve better performance by reducing the computation time and utilising the ARM cores efficiently.
Multi-threaded PS only solution: The initial PS-only solution is modified using a multi-threaded approach to make use of the four ARM cores available. The CNN block and LSTM block computations are parallelized using four threads and helped to bring down the computation time.
Key observations after profiling the multi-threaded PS-only solution are as follows:
- The multi-threaded implementation of CNN and LSTM blocks helped in considerably reduce the overall run time.
- Overall run time reduced from the initial 6.77 times to 1.887 times the audio length. This amounts to approximately 72% reduction in the run time.
- The CNN block now contributes to around 12% of the total run time.
- Still, the LSTM block is the major block in terms of computation time and consumes around 87% of the total computation time.
The next step is to offload some of the computations into the programmable logic (PL) and try to achieve more acceleration. As the major time-consuming block, the LSTM block is the ideal candidate for being accelerated in PL.
PS+PL solution (Single precision floating point): The major time-consuming operation in the LSTM block equations is the matrix-vector multiplication for every gate. There are two bottlenecks - the feedback nature of the computations and limited on-chip memory, which result in a high communication bandwidth requirement. These requirements are efficiently handled by using a variety of optimisations.
Fig 7. shows the top-level block diagram of the PS+PL implementation. The audio file is read from the SD card. Then feature extraction and CNN are processed on the PS, after which the LSTM block is executed entirely on the PL. The remainder of the pipeline is again executed on PS, and finally the predicted text is printed on a terminal using UART. External DDR memory is used to store the model weights and the intermediate results. These weights are fetched from DDR and stored locally in the on-chip BRAM.

Figure 7: Top level block diagram of the PS +PL diagram
The following points are derived from the profiling data:
- As expected, the time taken by feature extraction, CNN and post-LSTM blocks remain the same for both PS-only (4 threads) and PS+PL solutions.
- There is approximately a 62% speedup in the processing time for LSTM blocks after pushing ‘the LSTM layer on PL.
- The overall time taken by the complete pipeline is reduced to around 0.874 times the input audio length.
- Compared to PS-only (4 threads) there is a reduction of around 54% in the computation time.
- The PS+PL solution achieves less than 1x performance for different audio lengths.
- Real-time performance is achieved for the non-quantized and non-pruned model with Floating point precision.
The floating point implementation successfully achieved real-time performance.
Using edge-based AI for sound recognition
So far, we have looked at audio AI’s ability to recognise voice and speech. However, this type of technology has another important application area – analysis of machine sounds and vibrations. Anyone familiar with the necessity of maintaining a mechanical machine knows how important the sounds and vibrations it makes are. Proper machine health monitoring through sound and vibrations can cut maintenance costs in half and double the lifetime.
We can learn what the normal sound of a machine is. When the sound changes, we identify it as abnormal. Then we may learn what the problem is so that we can associate that sound with a specific issue. Identifying anomalies takes a few minutes of training, but connecting sounds, vibrations, and their causes to perform diagnostics can take a lifetime.
To address this, Analog Devices has developed a system that can learn sounds and vibrations from a machine and decipher their meaning to detect abnormal behaviour and to perform diagnostics. The system is called OtoSense - a machine health monitoring system that allows a computer to make sense of the leading indicators of a machine’s behaviour: sound and vibration.
The system applies to any machine and works in real time with no network connection needed. It has been adapted for industrial applications and it enables a scalable, efficient machine health monitoring system. The system can perform recognition at the edge, close to the sensor. There should not be any need of a network connection to a remote server for decision-making.
The OtoSense process comprises four steps - analogue acquisition of the sound, digital conversion, feature extraction, and interpretation.
Analogue acquisition and digitization: In OtoSense, this job is performed by sensors, amplifiers, and codecs. The digitization process uses a fixed sample rate adjustable between 250 Hz and 196 kHz, with the waveform being coded on 16 bits and stored on buffers that range from 128 samples to 4096 samples.
Feature extraction: OtoSense uses a time window called a chunk, which moves with a fixed step size. The size and step of this chunk can range from 23 ms to 3 s, depending on the events that need to be recognised and the sample rate, with features being extracted at the edge.
Interpretation: OtoSense interaction with people starts from visual, unsupervised sound mapping based on human neurology. OtoSense shows a graphical representation of all the sounds or vibrations heard, by similarity, but without trying to create rigid categories. This lets experts organize and name the groupings seen on screen without trying to artificially create bounded categories. They can build a semantic map aligned with their knowledge, perceptions, and expectations regarding the final output of OtoSense. The same soundscape would be divided, , and labelled differently by auto mechanics, aerospace engineers, or cold forging press specialists—or even by people in the same field but at different companies. OtoSense uses the same bottom-up approach to meaning creation that shapes our use of language.
Architecture: Outlier detection and event recognition with OtoSense happen at the edge, without the participation of any remote asset. This architecture ensures that the system won’t be impacted by a network failure, and it avoids having to send all raw data chunks out for analysis. An edge device running OtoSense is a self-contained system describing the behaviour of the machine it’s listening to in real time.
The OtoSense server, running the AI and HMI, is typically hosted on premises. A cloud architecture makes sense for aggregating multiple meaningful data streams as the output of OtoSense devices. It makes less sense to use cloud hosting for an AI dedicated to processing large amounts of data and interacting with hundreds of devices on a single site.
From Features to Anomaly Detection: Normality/abnormality evaluation does not require much interaction with experts to be started. Experts only need to help establish a baseline for a machine’s normal sounds and vibrations. This baseline is then translated into an outlier model on the OtoSense server before being pushed to the device.

Figure 8: Analog Devices’ OtoSense system
Conclusion
After showing the wide range of applications now amenable to voice, speech, or sound recognition applications, we have looked at some of the underlying AI algorithms – and how they are used as building blocks within the DeepSpeech2 package.
The Automatic Speech Recognition using DeepSpeech2 is also interesting for its choice of hardware – the Zynq UltraScale+ MPSoC. While this device lets users improve performance by moving some of the processing load onto programmable logic, it also allows optimisation of the power management. It is this type of technology that is making small, edge-based implementation of AI systems feasible.
OtoSense expands the field by showing how this type of technology can be used in sound recognition for machines, as well as human speech and voice recognition applications.
Designers interested in becoming involved with this technology can benefit from speaking to Farnell. We have a range of devices and development kits from several semiconductor manufacturers and can discuss their suitability for your particular application.
Stay informed
Keep up to date on the latest information and exclusive offers!
Subscribe now
Thanks for subscribing
Well done! You are now part of an elite group who receive the latest info on products, technologies and applications straight to your inbox.

Raspberry Pi solutions kits
Master the power of AI with Raspberry Pi for your personal and professional AI projects!
Related Articles
- Advanced ML for MEMS Sensors: Enhancing the Accuracy, Performance, and Power consumption
- How to design a MEMS Vibration Sensor for predictive maintenance
- Precision in Sight: How AI-powered visual inspection improves industrial quality control
- How to Capture High-Quality, Undistorted Images for Industrial Machine Vision
- Robotics and AI Integration: Transforming Industrial Automation
- The modern challenges of facial recognition
- Intelligent cameras for smart security and elevated surveillance
- Evolution of voice, speech, and sound recognition
- AI and IoT: The future of intelligent transportation systems
- Machine Vision Sensors: How Machines View the World
- Demystifying AI and ML with embedded devices
- How to implement convolutional neural network on STM32 and Arduino
- How to do image classification using ADI MAX78000
- The Benefits of Using Sensors and AI in HVAC Systems
- Deep learning and neural networks
- Latest Trends in Artificial Intelligence
- Hello world for Machine Learning
- How to implement AR in process control application






